Intelligent Virtual Humans
What is a Virtual Human?
Virtual humans are interactive digital characters that users can engage with in realistic 3D environments, including virtual, mixed, and augmented reality environments. They can be used as avatars to represent users or they can present an AI resulting in an intelligent virtual agent (IVA). To create a believable experience, these virtual humans leverage physics-based character control, ensuring their movements and interactions mimic real-world physics. Action classification enables these characters to recognize and respond to user inputs in a contextually appropriate manner. To enhance realism further, 3D avatar reconstruction from images allows for the creation of personalized avatars that accurately represent users. They also utilize AI and natural language processing (NLP) to engage in conversations, understand emotions, and respond appropriately to users. Together, virtual humans aim to bridge the gap between the real and digital worlds by facilitating more natural and intuitive interaction with digital environments and enhancing user experiences in areas such as entertainment, education, customer service, and beyond.
This technical pillar focuses on the research, design, and development of advanced methods to create realistic humanoid 3D models utilizing cost-efficient technology. These models will serve as avatars for users, known as Smart Avatars (SAs), or artificial agents, known as Intelligent Virtual Agents (IVAs). The primary focus lies in enabling natural, multimodal communication and interaction through a range of expressive capabilities, including speech, facial expressions, gaze tracking, and full-body animations. By enhancing the realism and responsiveness of virtual characters, this technical pillar strives to facilitate effective human-computer interaction, ultimately leading to more engaging and intuitive user experiences. Furthermore, the objectives extend beyond basic human-human communication, aiming to integrate hybrid interaction models that involve multiple real and virtual participants operating alongside SAs and IVAs.
What It Can Do (The Technology Behind the Magic)
1. Humanoid 3D Models (DIDIMO): To create Intelligent Virtual Humans (IVH), a crucial aspect is accurately modeling human appearance in 3D. Ideally, this should be achievable quickly using simple camera images, like those from mobile phones. Achieving this involves employing AI algorithms to identify optimal facial poses for creating blendshapes from RGB and depth video frames. Additionally, neural rendering techniques are used to produce fully animatable characters with photorealistic visual fidelity. The outcome is highly realistic and customizable 3D virtual humans, which can be scaled at runtime and are designed to represent other humans and intelligent virtual agents (IVAs) in various real-world use cases.
2. Motion Tracking and Action Classification (JRS): To enable the contextual behavior of Intelligent Virtual Humans (IVHs), motion tracking, and real-time intelligent action classification algorithms are essential. Achieving this involves integrating 3D motion tracking data from devices like inertial measurement units (IMUs) in head-mounted displays (HMDs) with image-based sensor data, such as RGB or RGBD, as well as information about surrounding objects and environments. This integration creates a coherent representation of both recent actions and potential future actions of the IVHs. The system classifies user and smart avatar actions and can predict future actions, such as speaking, gesturing, grabbing objects, moving, or interacting with others. Accurate predictions are vital for ensuring low-latency, realistic animations, especially in immersive VR applications. Consequently, the action classification toolkit will investigate methods for few-shot action classification as well.
3. Speech and Facial Interaction (UHAM): To enable IVHs to engage in conversations with human users, understand human emotions, and respond appropriately to users’ requests, it is important to enable natural human-like speech and facial interactions with IVHs. This can be achieved by extending recent neural network advancements to analyze, process, and synthesize speech and facial expressions, enhancing the AI capabilities of humanoid 3D models. Using existing humanoid models from DIDIMO, the project will employ speech-to-text and text-to-speech synthesis to facilitate natural user communication with humans and agents.
4. Full Body Animations and Interactions: To create plausible human-agent interaction experiences, IVHs need to leverage physics-based character control, ensuring their movements and interactions mimic real-world physics. In this task, ARTANIM is focused on body-centered interaction and human-agent collaboration. Using the rigged virtual humanoid 3D models from DIDIMO, Intelligent Virtual Agents (IVAs) will learn to perform specific tasks by observing actors. This task builds on recent advancements in physics-based character animation, applying them to social interaction in XR, an area not previously explored. The task will advance AI-based XR, contributing to UX, usability, and presence evaluation, and is particularly important for demonstrators in Manufacturing Training and Health, where IVAs are crucial.
5. Multimodal Interactions: Combining the advantages of photorealistic humanoid 3D models, motion tracking, action classification, speech and facial interaction, and physics-based full-body animations, Intelligent Virtual Humans (IVHs) have the potential to revolutionize human-computer interaction by delivering highly immersive and context-aware experiences. These systems will be capable of perceiving and responding to complex social and environmental cues, enabling natural and lifelike human-agent interactions and collaborations. For example, consider the following scenario: A user interacts with their smart avatar in a virtual environment and notices a humanoid agent standing in the distance. The user greets the agent while raising their hand. The agent detects both the verbal greeting and the raised hand using advanced motion tracking and auditory processing. In response, the agent walks toward the user, maintains an appropriate social distance, and returns the greeting with a friendly gesture and a verbal response. This seamless exchange enables a natural, meaningful conversation to unfold, driven by the agent’s ability to interpret and adapt to the user’s actions and context in real-time.
Advantages (and challenges we solve):
1. Diverse 3D Humanoid Model Database: Representing and modeling the diverse human demography in 3D is challenging. During the first phase of the project, the DIDIMO team created a database with diverse humanoid 3D models by compiling technical requirements for models, rigs, and textures, addressing deliverables for pipeline integration, producing prototypes for testing, and analyzing aesthetic requirements for various use cases in collaboration with partners.

2. Upper-body Self-Representations (Smart Avatar):
UHAM has successfully developed the initial versions of smart avatars using DIDIMO’s character template for upper-body self-representations. These avatars include features such as natural facial expressions, gaze tracking, hand tracking, and lip sync. This development involves integrating various sensor feedback for motion tracking within the virtual reality head-mounted displays, specifically utilizing the Meta Quest Pro Headset and Meta’s Movement SDK. Ongoing research aims to achieve natural full-body self-representation and implement motion interpolation techniques to compensate for any missing sensory data during tracking.


4. Real-time Speech Interaction (please download the original video for audio output)
UHAM has successfully produced the initial versions of intelligent virtual agents (IVAs) using DIDIMO’s character template. This involves integrating AI-based services for seamless interaction between users and avatars, utilizing speech-to-text and text-to-speech technologies for smooth dialogue. The implementation of OpenAI’s large language models has enhanced the conversational capabilities of the IVAs, enabling contextually relevant and coherent dialogues. Looking ahead, the next steps include training models with audio recordings of specific speakers to personalize avatar and IVA responses, thus boosting user engagement and satisfaction.

4. Physics-based Animations and Interactions: Currently, two methods have been implemented for training with reference animations in UnityVR: a non-state-based method (Deep Mimic) and a state-based method (DReCon). The ARTANIM team has explored using DReCon to create embodied virtual characters that respond to interpersonal distances relative to a VR user. This method combines DReCon with motion matching, a technique for synthesizing navigation movements, and a path-finding algorithm to determine trajectories. This combination allows the generation of a ragdoll that navigates the environment and addresses interpersonal distances by, for example, facing a VR user while walking sideways or backward. The ongoing challenge is adapting this method to rigged characters of various sizes and proportions while maintaining high-quality movement synthesis.

5. Real-time Action Classifications: The first prototype of the JRS action recognition algorithm relies on detecting the user’s or smart avatar’s pose (skeleton) within a specific time frame. Initial activities focused on optimizing the pose estimation framework to infer actions, such as ‘raising hand,’ from keypoint relationships. JRS has significantly enhanced the runtime and quality of its framework for real-time human detection, tracking, and pose estimation by updating the pose estimation component from EvoSkeleton to the more advanced RTMPose. This update improved the runtime efficiency, reducing it by a factor of 2.5, allowing the estimation of poses for up to five people in real-time (within 40 milliseconds).

Key Features
1. Virtual Human Generation
Autonomous 3D Humanoid Model Generation: Develop algorithms to create fully-rigged virtual humans based on specified parameters such as gender, ethnicity, and age range.
Photo to Avatar Conversion: Allows users to generate avatars of themselves or others from photographs.
Character Editor: Enable editing of virtual humans, including adjustments to face, body, garments, and accessories based on user-defined parameters.
2. Virtual Human Language Processing
Speech-To-Text: Facilitate communication with virtual humans using voice interaction to convert spoken words into text.
Text-To-Speech: Generate and express dynamic content through virtual agents during voice interactions, enhancing user engagement.
Natural Language Processing: Support natural language conversations between users and virtual humans.
3. Virtual Human Face Animation
Lip-Sync: Synchronize the virtual human’s lip movements with the voice output for realistic interaction.
Facial Expression: Integrate eye movements and blinks using eye-tracking (for smart avatars) or algorithms (for intelligent virtual humans) to enhance natural user interaction.
Eye Movement and Blinks: Implement natural eye movements and blinking for a more lifelike virtual human experience.
4. Virtual Human Body Animation and Locomotion
Kinematic Imitator (State-Based Physics Controller): Train physics controllers to replicate kinematic movements, handling tasks such as locomotion, object interaction, and head-turning using kinematic methods. These controllers ensure adherence to physical constraints, such as inertia and obstacle collision.
Sensorimotor Controller (Non-State-Based Physics Controller): Utilize pure perception-action loops for interactive character reactivity. Though technically challenging, incorporating interactivity within the training process can result in more flexible controllers.
5. Recognition, Detection, and Tracking (Human, Emotion, and Object)
Human Action Recognition: Perform real-time recognition of human actions from 2D videos.
Facial Emotion Recognition: Implement real-time detection of emotions from a user’s face, even when they are wearing a headset.
Object Detection and Tracking: Conduct real-time detection and tracking of objects, such as faces or tools, from 2D video. Use an open-set (zero-shot) object detector to add new classes without retraining.
The Technology Behind It ( and the Main Components)
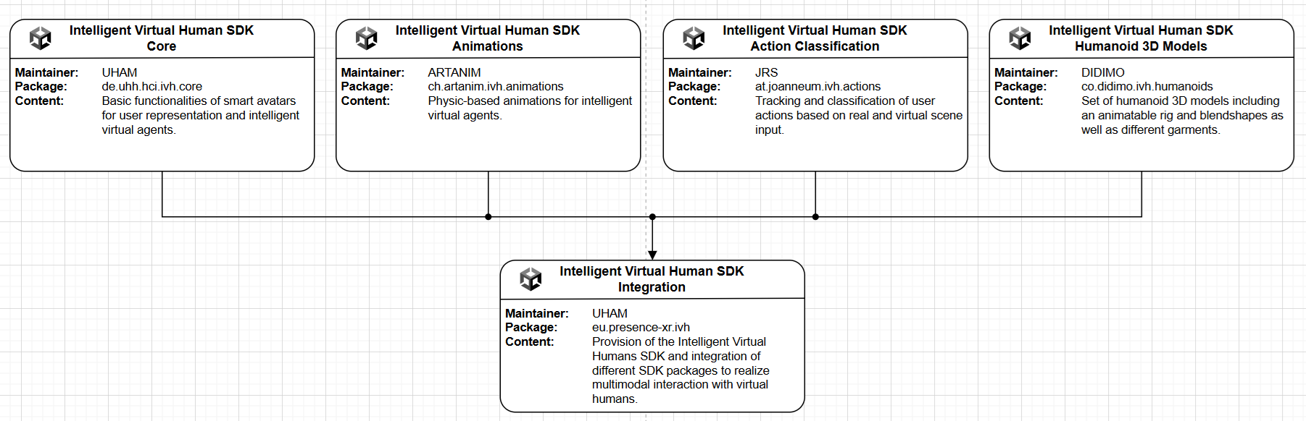
The Intelligent Virtual Human Software Development Kit (SDK) is built upon several core components, each playing a vital in the creation and functionality of IVHs. These components are designed to optimize performance, realism, and interactivity, enhancing the virtual human experience across various applications.
1. Intelligent Virtual Human SDK Core: This serves as the foundational framework that integrates all functionalities necessary for creating and managing intelligent virtual humans. It encompasses the architecture needed to support virtual human modeling, animation, interaction, and integration.
2. Intelligent Virtual Human SDK Animations: This component focuses on the animation aspects of virtual humans. It includes advanced algorithms for facial and body animations, ensuring seamless movements that mimic real-world physics. Physics-based character control is leveraged to provide lifelike interactions and expressions.
3. Intelligent Virtual Human SDK Action Classification: Action classification is critical for enabling virtual humans to recognize and respond appropriately to user inputs. This component utilizes motion tracking and real-time intelligent action classification to analyze user actions and predict subsequent interactions, thus facilitating a natural and immersive user experience.
4. Intelligent Virtual Human SDK Humanoid 3D Models: This aspect involves creating realistic 3D models using cost-efficient technologies. These models serve as avatars (Smart Avatars) or agents (Intelligent Virtual Agents) and are enhanced through AI algorithms to achieve photorealistic visual fidelity. The 3D models are customizable and scalable, designed to reflect diverse demographics authentically.
5. Intelligent Virtual Human SDK Integration: Integration is pivotal in ensuring that all components work cohesively within the virtual environment. This includes interfacing with hardware such as head-mounted displays, incorporating AI and NLP for speech and language processing, and ensuring compatibility with various platforms for seamless deployment.
Each of these components contributes to the overarching goal of intelligent virtual humans: to bridge the gap between the real and digital worlds through natural and intuitive interaction, thus transforming the user experience in fields like entertainment, education, and customer service. By focusing on innovation and responsiveness, these components enable virtual humans to engage users in a meaningful and contextually aware manner, creating an engaging digital environment.
Impact (where & how)
Focus on our use case markets (where) and highlight the how in them
The Intelligent Virtual Human project is poised to create significant impacts across various use case markets by advancing human-computer interaction and bridging the digital and real worlds. Here’s a look at the potential impact in key industries and how our technology enhances them:
1. Education and Training:
– Where: Classrooms, virtual training environments, and corporate training sessions.
– How: By providing immersive and interactive learning experiences, Intelligent Virtual Humans (IVHs) can serve as virtual tutors or training assistants. These virtual agents can adapt to individual learning paces, respond to questions, and create realistic scenarios for experiential learning. They are particularly beneficial for remote learning, offering engaging and personalized education even at a distance.
2. Entertainment and Media:
– Where: Video games, virtual reality experiences, animated films, and live virtual performances.
– How: Our technology can revolutionize the entertainment industry by creating highly realistic and responsive virtual characters. These characters can interact with players or audiences in real-time, enhancing storytelling and delivering a richer, more immersive entertainment experience. IVHs can also be used to generate dynamic content that adapts to audience reactions, fostering deeper engagement.
3. Healthcare and Therapy:
– Where: Digital therapy sessions, virtual patient interactions, and medical training simulations.
– How: IVHs can play a crucial in healthcare by simulating patient interactions for training medical professionals or providing support in therapy settings. They can also be used to desensitize patients in a controlled environment or conduct cognitive-behavioral therapy sessions. The ability to recognize and respond to emotional cues makes them valuable tools in providing empathetic and tailored care.
4. Customer Service and Support:
– Where: Virtual assistants on websites, smart kiosks, and mobile applications.
– How: By integrating Intelligent Virtual Agents, businesses can offer 24/7 customer support with personalized and efficient service. These agents can understand natural language, process and resolve inquiries, and provide recommendations in a human-like manner, improving customer satisfaction and operational efficiency.
5. Manufacturing and Industrial Training:
– Where: On-site virtual training environments, remote field training.
– How: IVHs can provide practical training and simulations in a risk-free environment. They can guide users through complex machinery operations or safety protocols, enhancing skills and safety awareness. Simulation of real-life scenarios prepares workers for real-world challenges, reducing error rates and increasing productivity.