Introduction
Among the many challenges and technologies involved in the PRESENCE project is the enabling of a multi-user conference session, where a group of people can see and interact with each other in real time. This holoportation system not only must ensure accurate visual representation of holoported individuals but also enable remote physical interaction between users through advanced haptic technology.
Volumetric Video (VV) plays a central role in enabling real-time holoportation, as it allows for the dynamic capture and rendering of 3D human representations. However, this technology is highly demanding in terms of computational resources and network bandwidth. Even with compression and image processing techniques applied before transmission, the bandwidth required for a single user can easily exceed 15 Mbps. In the worst possible scenario, where each client needs to receive the volumetric representations of all other participants, the amount of information transmitted grows quadratically, thus quickly leading to bandwidths over 1Gbps per session/conference. This makes it infeasible for servers to handle all the data reliably and resulting in transmission bottlenecks or loss.
i2CAT’s solution: Smart distribution of multi-user data with Levels of Detail
To tackle this problem, on i2CAT we developed our own Volumetric Video Selective Forwarding Unit (SFU): An SFU handles the efficient routing of the fluxes of data from one user to the rest of users that are on the same session. Therefore, the SFUs instances need to be deployed on the edge of the network. SFUs are considered one of the standards for managing real-time communications and their capabilities may vary depending on the targeted use and particular implementation and there are numerous implementations, as this concept is considered one of the standards for managing real-time communications.
When using only one SFU applied to the Holoportation use case, we found out that the network workload was saturated easily. The first approach to solve this was to deploy multiple SFUs, assigning a small number of users to each one, which in turn would distribute their information to everyone else in the session. Thus, we reduced the received and transmitted bandwidth, as only a fraction of the session data had to be routed by each module, considerably decreasing the workload on server-side.
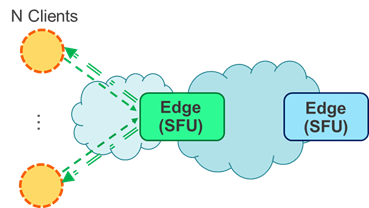
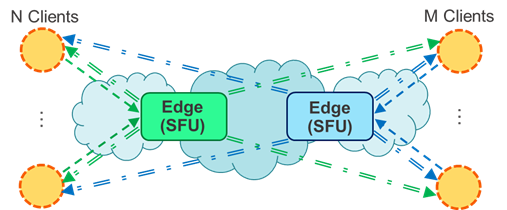
Figure 1. Only using 1 SFU (left), and using 2 SFUs (right).
Our results show that for each new module introduced into the multiple SFU system, we improved by 1.5x the amount of users that could be present in one session without server overload. However, we also found out that there were drawbacks: even though we were able to reduce the amount of incoming data per SFU, each module still had to distribute said information to the rest of the participants. Therefore, transmitted data still scaled in cost with the amount of users. This raised the need to create a Level-of-Detail (LoD) system to strategically reduce the transmitted data. Most LoD systems take advantage of the Field of View (FoV) of the user: Intuitively, whichever users are outside the client’s FoV or too far away don’t need to send as much of a detailed representation if they even have to send information at all. Therefore, we established a range of qualities, ranging from no data being sent for users that can’t be seen by the client, to maximum detail when they are close and centered to the FoV. The Levels of Detail were established according to a subjective study we realized of the perceived quality at each distance with different compression levels.
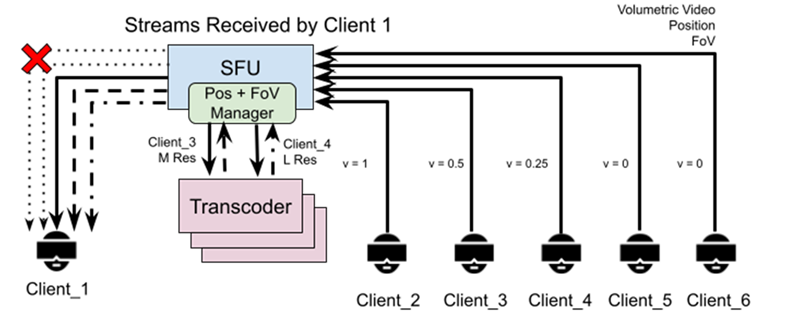
Figure 2. SFU with usage of ViewPort-aware system and Transcoder
In Figure 2, we describe the inner workings of the Fov Manager system. In this example we take Client 1 as the receiving user and each of the other clients’ visibility is represented as a parameter (v) ranging from 1 (completely visible) to 0 (completely non-visible). We see how for Clients 5 and 6, the SFU doesn’t send their data to Client 1 as they are not perceivable at all by it. Therefore, we decrease the load on the transmitter.
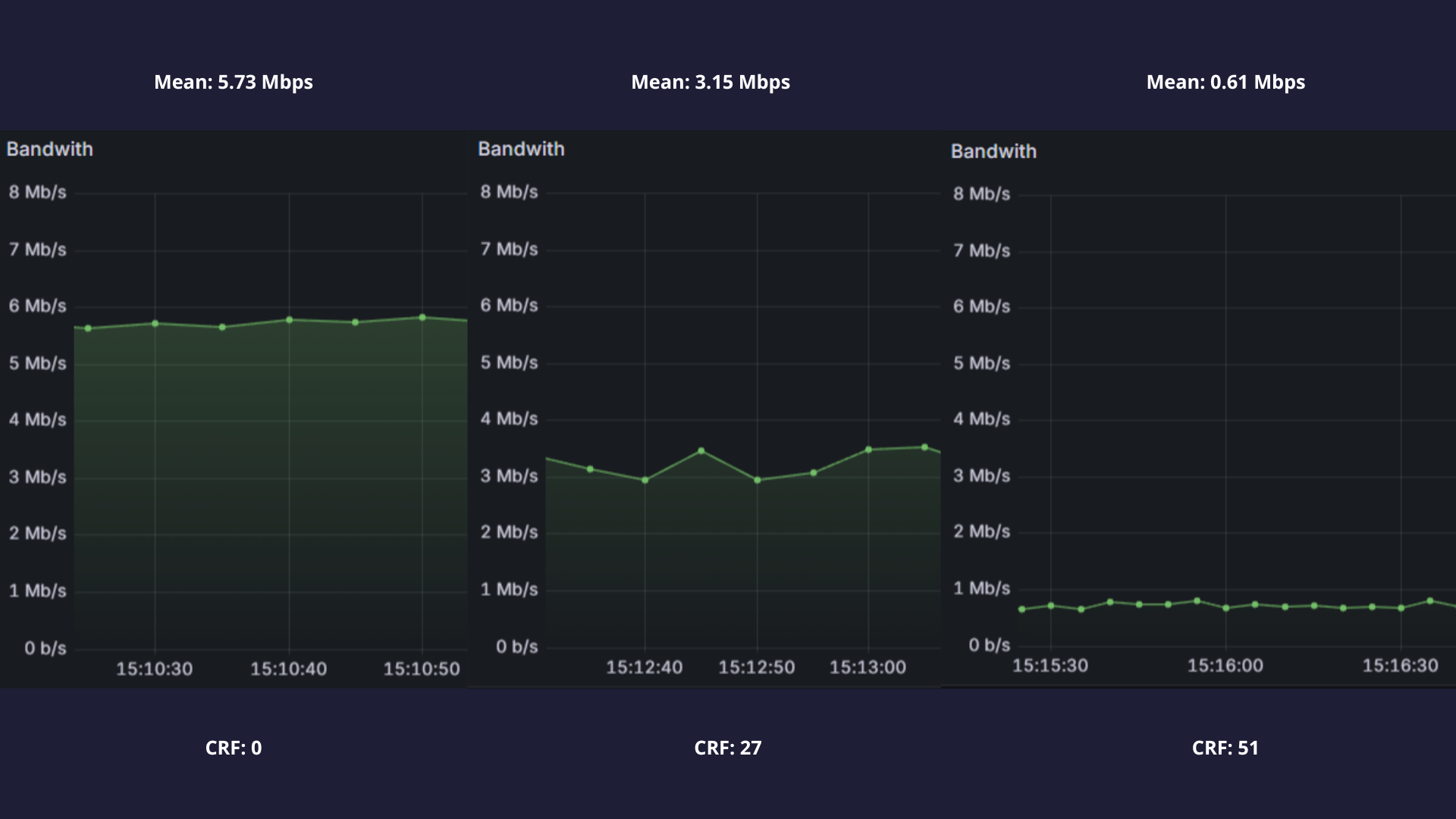
Figure 3. Transcoder changes in levels of detail dynamically according to the visibility parameter.
Additionally, going one step further away from pruning unperceivable data, we introduce a separate server module, the Transcoder. This module communicates directly with the SFU and receives both the users’ data in full quality as well as the desired LoD. Then, the transcoder recompresses said data to a lesser quality but lighter format and returns it to the SFU so it can be distributed to the required users. Figure 2 shows how depending on the view level (the v parameter), the information transmitted to the client is reduced (represented as a less-continuous line). This results in up to 4x less bandwidth being used, which allows for more users to be in the same session without the need of an expensive and powerful internet connection and, more importantly, without loss of perceived quality as we are only removing redundant detail in specific situations. Figure 3 displays the dynamic change between the LoDs seen in Figure 4 according to the visibility parameter and how that reduces the bandwidth used from 50Mbps to around 15Mbps. It is key to note that the loss of detail (like the eyes and mouth disappearing from view) is in practice not noticeable at the distances where that LoD is used according to our user studies.

Figure 4. A visual comparison of the different qualities. Highest quality (left) Medium quality (middle) Low quality (right).
Having presented our solution, we at the I2CAT Foundation are still working to improve VV communications by experimenting with multiple modules and combinations to provide the best possible experience while consuming the least amount of resources possible. As we make further improvements, we will update you in the near future. Stay tuned!