by Hannes Fassold – JOANNEUM RESEARCH
In the swiftly changing field of eXtended Reality (XR), the pioneering research project, PRESENCE, aims to expand the limits of what can be achieved. This blog post spotlights a significant technical feature of the project: Intelligent Virtual Humans and how AI can improve interactions with them. As one of PRESENCE’s three foundational technology pillars, they are set to transform the ways we collaborate, train, and interact in virtual environments.
Intelligent Virtual Humans are highly realistic digital figures designed to replicate human behaviour and appearance. They can act as advanced avatars, providing users with embodied self-representations in virtual settings, or as intelligent virtual agents, representing sophisticated, human-like avatars. Within PRESENCE, these Intelligent Virtual Humans are backed by advanced AI and neural network technologies, enabling them to interact with users in a natural and effective manner. The developed technologies will be evaluated in four different use cases: Online collaboration in an XR environment, manufacturing training, providing a lifelike cultural entertainment experience and sharing a virtual space for pain relief during medical treatment.
Role of JOANNEUM RESEARCH in PRESENCE
Within PRESENCE, JOANNEUM RESEARCH is focused on developing advanced AI methods to accurately predict and categorise what users are doing and planning to do in various situations. By combining 3D motion data, image-based sensor data, and information about the surrounding environment with object detection and tracking, JRS creates a system that can understand recent actions in real-time. This sophisticated approach allows the system to accurately identify user behaviours, predict future actions, and smoothly enable immersive animations with minimal delay, enhancing user experience significantly. An important aspect is also that the AI methods have to be real-time capable, which necessitates the research in efficient neural network architectures as well as methods for reducing the model size (e.g. via pruning or quantization).
Since actions are specific to different use cases, JOANNEUM RESEARCH explores methods to train classifiers effectively even with limited data, ensuring the system’s versatility and reliability across various applications. Additionally, we will research ways to explain how the AI models work internally using techniques like feature relevance propagation or class activation maps, providing transparency and understanding of the decision-making processes within the AI. This comprehensive research and development effort aims to create a robust, user-friendly AI system that can be utilized in numerous fields, from gaming and virtual reality to professional training and beyond.
JOANNEUM RESEARCH is well positioned for its research in PRESENCE, as it has gathered broad experience in many fields of AI and computer vision, ranging from supervised and unsupervised learning, object detection and tracking, image and video enhancement, transfer learning, compact neural networks, generative AI, large language models, explainable AI, efficient training and much more.
For the research work in PRESENCE, JOANNEUM RESEARCH will base upon research done in object detection and tracking, action recognition, pose estimation and explainable AI. In the following, we will briefly the research we build upon.
Object detection and tracking
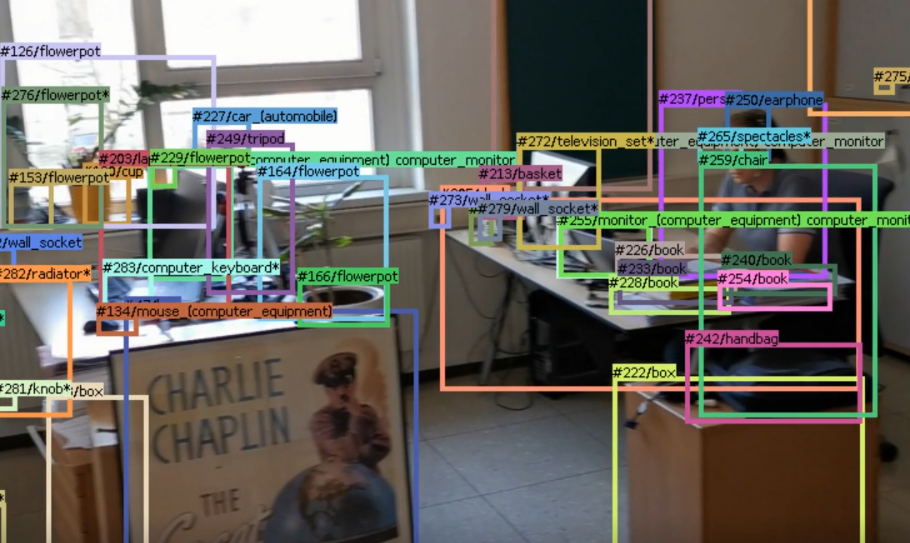
For object detection and tracking, we developed a real-time capable algorithm relying on state-of-the-art object detection algorithms (like Detic or Yolo-V7) coupled with optical-flow-based tracking. The following figure illustrates the algorithm, employing Detic as an object detector which is able to detect more than one thousand different object classes.
Action recognition
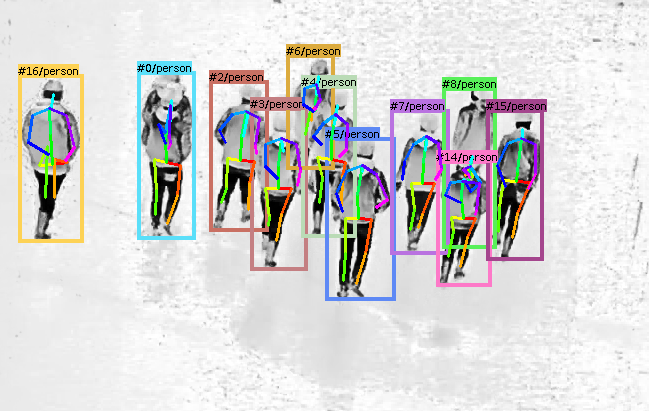
For action recognition, we developed a real-time algorithm for human action recognition which works both on RGB and thermal cameras. It is able to recognize four basic actions (standing, walking, running, lying) in real-time on a notebook with an NVIDIA GPU. For this, it combines state-of-the-art components for object detection (Scaled-YoloV4), optical flow (RAFT) and pose estimation (EvoSkeleton). An example of a thermal video can be seen below.
Explainable AI
For explainable AI, we did research on explaining the decisions of a state-of-the-art face-recognition pipeline. A novel set of well-located and easily interpretable image features named Locally Interpretable Boosted Features (LIBFs) has been researched and experiments show that these features lead to better interpretation (see the visualization below).
