CERTH’s Technology Behind Real-Time Human Holoportation in PRESENCE
By: Theofilos Tsoris – CERTH
Imagine stepping into a virtual world where the people around you look, move, and react exactly like they do in real life. That’s no longer a distant dream—it’s happening right now.
Many XR experiences still feel a little “off” because 3D reconstructed humans don’t fully capture the nuances of real bodies. It breaks the illusion and reminds us that we’re only in a simulation.
The PRESENCE project changes everything by advancing, among others, human reconstruction technology, bringing realistic volumetric models into XR spaces. In this post, we’ll dive into how human reconstruction plays a crucial role in creating truly immersive XR experiences—and how it fuels the future of Holoportation.
You’ll discover how PRESENCE is setting new standards for realism, interaction, and emotional connection in virtual environments.
Volumetric human reconstruction at CERTH

Real-world captured actor (left) and its 3D reconstructed counterpart (right) in CERTH’s Visual Computing Lab.
At the Visual Computing Lab @ CERTH (Center for Research & Technology), our team has been pushing the boundaries of human volumetric reconstruction through cutting-edge research and development. Our work focuses on creating high-fidelity volumetric reconstructions that capture human figures with detail and realism. To achieve this, we combine a series of advanced techniques across multiple stages of the reconstruction pipeline.
Starting with volumetric reconstruction, we use sophisticated geometry filling algorithms that intelligently complete missing parts of the 3D model. This step is essential because real-world captures often contain occlusions—areas where parts of the body are hidden from some cameras. These gaps, if left unresolved, can break immersion. Our algorithms automatically detect and fill these missing areas, producing smooth, fully-formed 3D surfaces that appear complete and natural in virtual environments.
But geometry alone doesn’t make a model realistic—how it looks is equally important. That’s where our multi-view texture mapping comes in. We combine images captured from multiple camera angles and apply a weighted averaging method to project the most consistent and visually accurate texture onto the 3D model. This means details like skin tone, fabric texture, and lighting transitions are balanced and coherent across the entire surface. The result is a high-fidelity digital human that not only moves realistically, but also looks lifelike from every angle—crucial for preserving immersion in XR experiences.
Beyond just static geometry, temporal and spatial calibration play a vital role. Temporal calibration ensures that all frames captured by different cameras are perfectly synchronized—even during rapid movements—using sophisticated software synchronization methods. Spatial calibration, meanwhile, ensures that every camera’s view aligns flawlessly with the others. More details in calibration and volumetric reconstruction techniques are given in the section Our Contribution to PRESENCE below.
Finally, to bring reconstructed humans into immersive experiences, we either render in our application the volumetric captures for immediate viewing or we stream the data directly to real-time renderers such as Unity. This tight integration means that human models appear in virtual worlds almost instantly, preserving motion, texture, and fine details that make the experience feel truly alive.
At CERTH, our vision is to make human reconstruction not only more accurate but also more accessible, helping to unlock new possibilities for XR experiences across telepresence, training, holoportation, and beyond.
“Perfection lies in the details; to craft reality with precision, we must see clearly beyond the surface.
— Theofilos Tsoris, Computer Vision Researcher
Our capturing and reconstruction platform
To support our human reconstruction research, we developed Volcap—our all-in-one platform for volumetric capture and reconstruction. Volcap is the heart of our workshop, bringing together all the essential tools needed to capture, reconstruct, calibrate, and tweak complex scenes with multiple RGB-D cameras. It’s designed to manage every aspect of configuring such a sophisticated volumetric system, making even the most complicated setups smooth and accessible.
At its core, Volcap is a multi-sensor capturing system built with a clear philosophy: use low-cost, commodity hardware without sacrificing performance. It’s quick to set up thanks to automatic sensor connectivity that scales effortlessly with the number of cameras. It’s also easy to deploy because it requires no markers for calibration—just a quick and smart sensor alignment process. Every part of Volcap, from deployment to hardware configuration, is fully documented to ensure flexibility and ease of use.
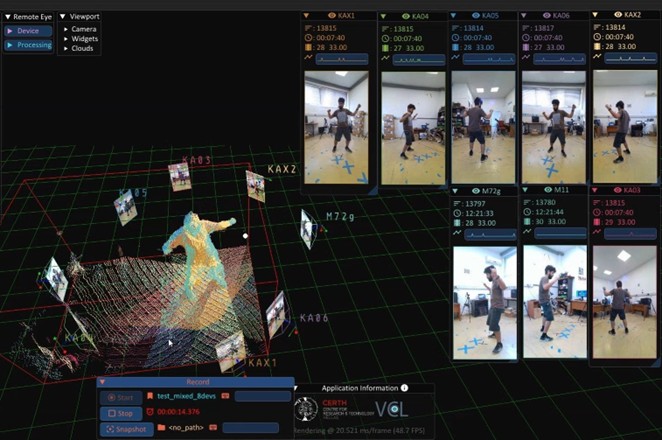
Snapshot of the VolCap application in a multi-camera setup in action.
Technically, Volcap operates as a distributed system. Each camera, or “Eye,” runs a lightweight, headless application to manage and collect its data independently. All these Eyes are coordinated by the central VolCap UI, which acts as the control center for the entire sensor network. Data communication is handled by a broker system, ensuring fast, reliable, and flexible operation across setups of different sizes.
Among its major strengths are efficient and scalable live data acquisition across multiple streams, the ability to mix and integrate devices like Kinect Azure and Orbbec RGB-D cameras and precision synchronization using both hardware and software timing standards. Through data-driven global calibration methods, Volcap achieves highly accurate volumetric alignments, ensuring that the 3D reconstructions are both seamless and life-like.
With Volcap, we are making complex volumetric capture accessible and reliable—paving the way for creating richer, more realistic XR experiences.
Our contribution to PRESENCE
At PRESENCE, our contribution focuses on making virtual humans feel real. To achieve this, we combine deep research into some of the most advanced 3D reconstruction techniques available today. One of the first steps in our pipeline is to manage the enormous flow of data generated by depth sensors and RGB cameras. We initially used Fast Fourier Transform (FFT) algorithms to quickly process and organize the complex data captured by these sensors and cameras. While effective, this approach offered limited flexibility when fine-tuning for the many variables involved in high-quality 3D modeling. To better address the intricacies of human reconstruction, we developed an innovative processing pipeline. This pipeline gives us the parameterization control, modularity, and rapid experimentation cycle needed to iterate and optimize quickly. With a multitude of parameters to adjust—ranging from sensor noise filtering to depth thresholding and algorithmic specific parameters—this tailored setup allows us to fine-tune each stage of the reconstruction process for maximum fidelity and robustness.
Before we can build any surface, we first need to clean up the raw volumetric data—and that’s where the Fast Winding Number algorithm comes in. This technique works on the entire volume, helping to determine which areas are truly “inside” the object and which are outside. By doing so, it produces a cleaner, more coherent 3D volume—removing noise, filling geometry gaps, and resolving ambiguities. This refined volume forms a much more reliable foundation for the next step, where the Marching Cubes algorithm steps in to extract a smooth, solid surface. Getting the volume right is essential—because even the best surface extraction can only go so far if the underlying data is messy or unclear.
Subsequently we use a Marching Cubes algorithm, a classic yet powerful method that transforms 3D volumes into solid, coherent surfaces. Imagine starting with a block of invisible fog—this fog is a volume, a 3D grid filled with values that hint at where a surface might exist. Marching Cubes works like a sculptor, carving out the visible shape hidden within that fog by connecting these clues into a clear, usable 3D model. It’s the essential bridge between raw volumetric data and something we can actually see and interact with in virtual space. Once we have the 3D geometry in place, we “breathe life into it”, so to say, by applying high-quality textures. These textures are applied using a multi-view blending approach with weighted averaging, which not only captures accurate skin tones and clothing details, but also preserves ambient lighting and smooth color transitions between sensor views. This technique creates the illusion of a seamless, coherent 3D human—even though each camera captures the subject from a different angle and potentially different lighting—ensuring visual consistency across the entire reconstructed model. Combined with the underlying 3D geometry, this process merges visual and spatial data into a unified, volumetric representation of the human body—realistic in both appearance and motion. This makes the final models look remarkably close to real people, enhancing emotional connections and natural interactions within XR environments.
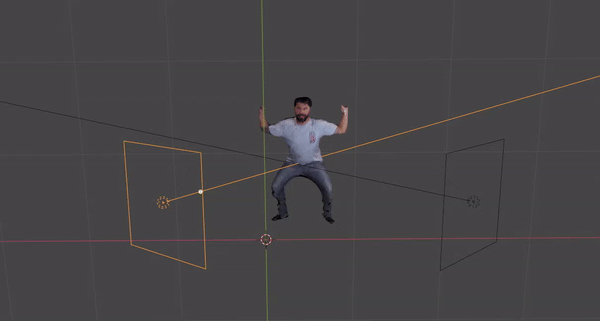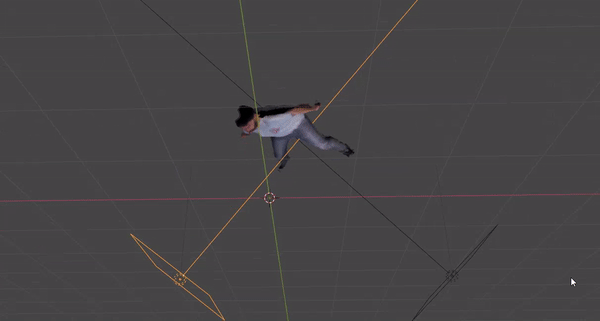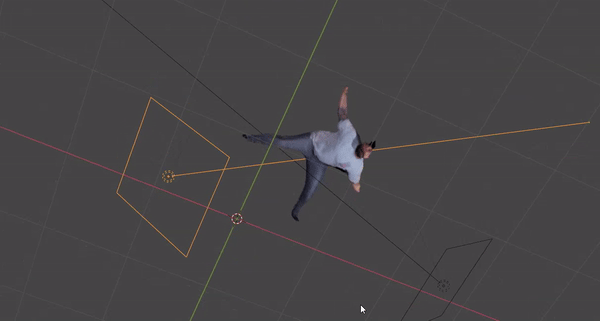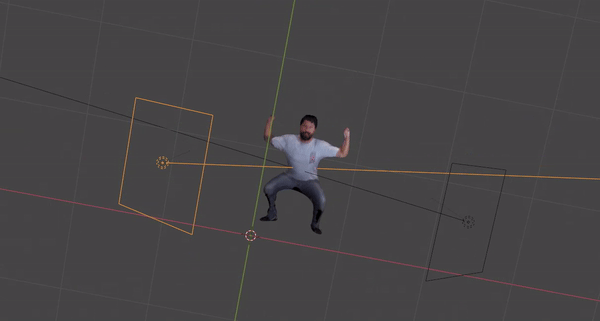
Volumetric reconstruction of an actor in the scene with the latest pipeline.
Temporal calibration—making sure that all cameras stay perfectly in sync across time—is handled through our custom wireless software synchronization system. Instead of relying on expensive synchronization hardware, we use a clever software-driven approach that keeps multiple distributed cameras tightly aligned in time, even when capturing highly dynamic movements. Moreover, the cameras’ shutters are hardware-synchronized to capture frames at the exact same moment, ensuring perfect alignment across all viewpoints.
For spatial calibration, we combine the best of traditional and modern techniques. We use traditional Computer Vision techniques to set an initial calibration baseline, placing fiducial markers within the scene to ensure consistent alignment across all camera views. Then, we enhance the precision by incorporating neural network models that can adaptively learn and refine spatial relationships between the sensors. In addition, we apply Generalized Iterative Closest Point (GICP) algorithms to refine the alignment using depth data for greater precision. To ensure consistency across the entire sensor network, we also use global registration algorithms such as Bundle Adjustment and g2o, which optimize the overall alignment of all cameras in the system. This multi-layered approach ensures that all the cameras work together as a single, highly accurate capturing system.
Our meticulous, multi-step process means PRESENCE can create authentic, fully-formed digital humans that move, appear, and react as naturally as their real-world counterparts. This realism is key not just for visual fidelity, but for enabling real-world applications across our four core use cases: professional collaboration, manufacturing training, health & well-being and exploring cultural heritage. The better the virtual representation, the stronger the feeling of presence — the sensation of truly “being there” with someone, even across great distances.
Ultimately, our work on human reconstruction is a fundamental part of the PRESENCE vision: to overcome technological limitations and make XR experiences feel as seamless, emotional, and impactful as real-world interactions.
Conclusions
Through our dedicated research and innovation at the Visual Computing Lab @ CERTH, we are proud to be shaping the future of human reconstruction within the PRESENCE project. By advancing volumetric capture through the Volcap platform, combining state-of-the-art algorithms for spatial and temporal calibration, and seamlessly integrating real-world humans into XR environments, we are breaking technological barriers that once limited immersive experiences. Our focus on accuracy, efficiency, and accessibility—using affordable hardware, intelligent synchronization, and deep learning-enhanced calibration—brings high-quality human representations closer to everyday applications. As part of PRESENCE, our work contributes directly to making virtual interactions more authentic, emotional, and impactful, helping transform XR into a natural, powerful extension of real-world human connection.
Share & Follow
For any inquiries, please contact:
Theofilos Tsoris (ttsoris@iti.gr)