by Werner Bailer – JOANNEUM RESEARCH
Introduction
Extended Reality (XR) applications such as those developed in the PRESENCE project rely – among many others – on two important enabling technologies: 3D content representations of scenes and objects, and AI technologies for enabling perception and interaction. Both of them involve large amounts of data, and compression technologies can make the exchange of this data more efficient in terms of network bandwidth and energy consumption.
MPEG, the Moving Pictures Experts Group, is an ISO/IEC standardisation group well known for multimedia coding standards, widely used for video and audio content. Addressing the trend of adopting AI methods based on neural networks for many multimedia tasks, MPEG has been working on a standard for coding neural networks in the past years. The group on neural network coding (NNC) is chaired by Werner Bailer from JOANNEUM RESEARCH.
Efficiently representing trained neural networks
Artificial neural networks, which aim to mimic biological networks of neurons, have been known for decades. The computational and data resources to scale them to many layers (i.e., make them “deep neural networks”) has enabled the recent success of AI. The description of a network contains of the topology, i.e. which types of layers are used and how they are connected, and its parameters. The network parameters may be weights (i.e. values to be multiplied with the input value at a particular position), biases (values to be added) and some more specific kinds for some layer types. The network parameters are represented as a tensor – think of a matrix as a rectangular grid of numbers, and then extend this to a box to get a 3D tensor (and possibly adding further dimensions). The numbers are typically floating point values, as covering wide value ranges with high accuracy is needed during the training process.
However, not all numbers in the parameter tensors are equally meaningful. Some may have small values, and considering them as zero does not change much. Others could be represented with lower precisions, or there may be repeated patterns of values in a neighbourhood. This is where neural network coding comes in: making use of redundancy in the parameter tensors in order to represent them more efficiently.
The NNC standard focuses on compressing the parameters of trained neural networks by specifying a toolbox of compression tools, from which a subset can be chosen for a particular application. These tools include parameter reduction tools, such as pruning (i.e., removing sets of parameters with low contribution), parameter quantisation tools (i.e., representing values on a coarser scale), and entropy coding tools (i.e., representing more frequent values or sequences of values with a more compact code).
A second edition of the standard, supporting a larger set of coding tools and incremental updates of neural network parameters, was completed in 2024 [1], and the part on conformance testing and a reference software were added earlier this year. Figure 1 shows the encoding and decoding pipeline for incremental neural network updates.
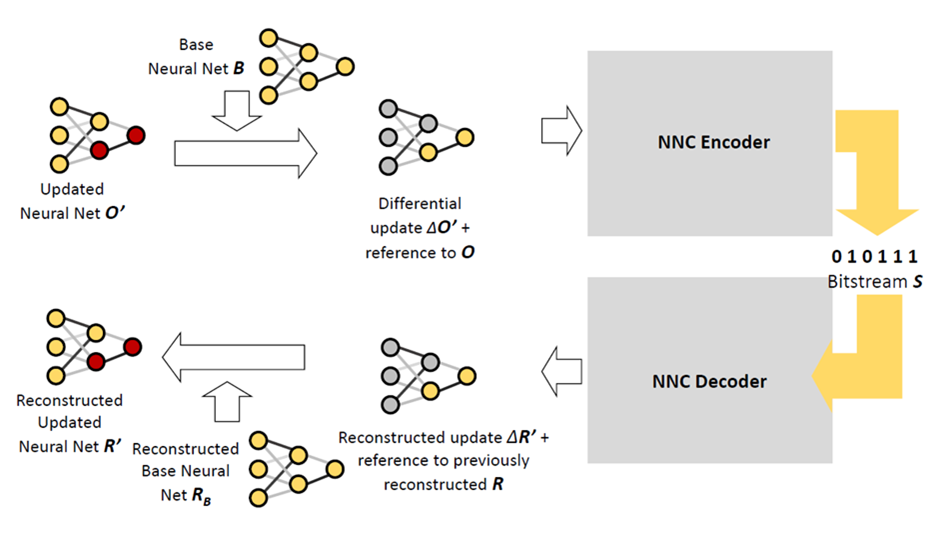
Figure 1: Compression pipeline for efficiently compression updates of trained neural network parameters.
The compression technology can for example be used to train neural networks for object detection, action recognition or movement control of avatars in XR applications. If the neural networks are updated, e.g., in order to be more robust in new environments or add new categories of actions, the update can be efficiently distributed without resending the entire set of neural network parameters. More information can be found in the white paper on the standard [2].
Novel 3D content representations
In addition to points clouds and (textured) meshes, new representations for 3D scenes have emerged in recent years, most notably neural radiance fields (NeRFs) and 3D Gaussian splatting (3DGS). NeRFs differ from traditional representations as they represent the light field of a scene. A NeRF represents the scene as the parameters of a trained neural network, and elements of the scene cannot be directly accessed, but only views of the scene can be rendered by performing inference of the neural network. As it is a neural network, NNC can be naturally applied to compress this scene representation. It has been demonstrated that a scene can be compressed to 10-20% of its original size using NNC out of the box without fine-tuning (reports of application of NNC several types of data can be found in [3]).
3DGS produces a point cloud and a set of fitted parameters representing primitives around these points (ellipsoids in the original algorithm, more recently also triangles). While NNC can be applied to other types of tensorial data – such as these parameters of 3DGS – MPEG has also started exploring the use of existing volumetric video and point cloud codecs to develop an efficient codec for 3DGS [4].
[1] ISO/IEC 15938-17:2024, Information technology – Multimedia content description interface – Part 17: Compression of neural networks for multimedia content description and analysis, https://www.iso.org/standard/85545.html
[2] White Paper on Neural Network Coding, https://www.mpeg.org/wp-content/uploads/mpeg_meetings/145_OnLine/w23564.zip
[3] ISO/IEC JTC1 SC29 WG04 N0696, “Application and Verification of NNC in Different Use Cases,” Jul. 2025, https://www.mpeg.org/wp-content/uploads/mpeg_meetings/151_Daejeon/w25474.zip